Search Engine Architecture
The architecture is based off of a 2001 paper (Searching the Web) by Arasu et al. published by the Association for Computing Machinery
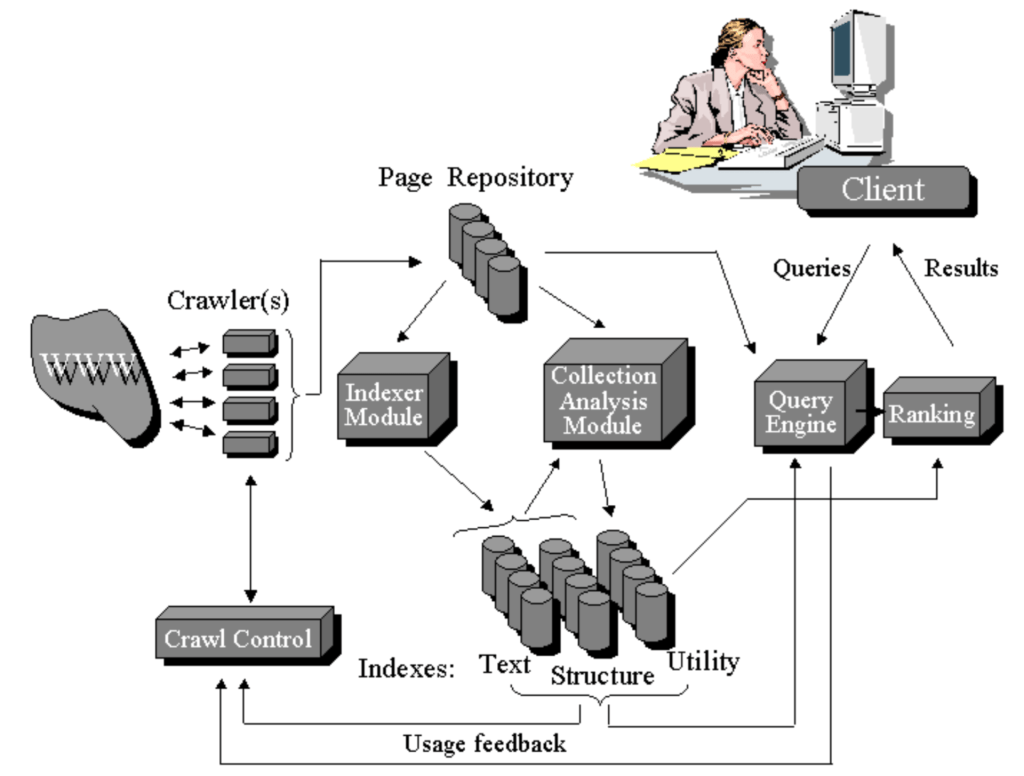
A schematic describing different components of the search engine design (from Arasu et al.)
Crawler(s) and Crawl Control
The crawler(s) browse(s) the web for the search engine, similar to how a human would follow links to reach different pages. The crawler starts at a specific root URL and starts the recursive process of extracting hyperlinks crawling these additional webpages. The crawler caches each retrieved page into a page repository. The crawler will continue visiting webpages until local resources are exhausted (i.e. no more storage in the page repository.
Indexer Module
The indexer module extracts all of the words from each page, and records the URL where the word occurred. This process creates a large lookup table which provides all of the URLs that point to pages where a given word occurs. Furthermore, the indexer also keeps track of the number of occurences per page, allowing for tracking pages with a large number of keywords on the single page.
Querier Engine Module
This module is responsible for receiving and fulfilling search requests from users. It uses the page indexes to get a list of URLs which contain the keywords in the query. Then the module ranks pages based on the number of occurrences of keywords in the user query.
Implementation
See GitHub Repository for the source code.
Crawler Implementation
In this implementation, we use a single crawler to browse the webpages. The implementation is a standalone program which crawls the web starting from the seed url, fetches links from webpages continuing to a certain depth, and then caches these webpages in a specific page directory. The crawler ignores duplicate webpages when it scans each page for URLs. Furthermore, it has guardrails in-place to prevent it from crawling the entirety of the web (we don’t want to crawl pages that didn’t give us permission ;) )
Usage:
$ ./crawler seedURL pageDirectory maxDepth
Here we see the verbose output of the program:
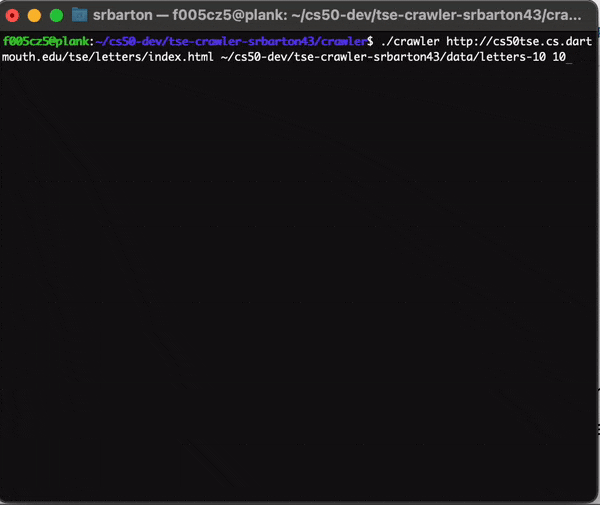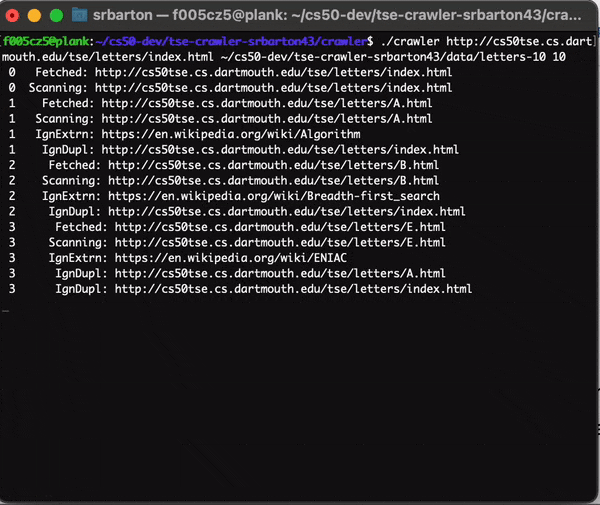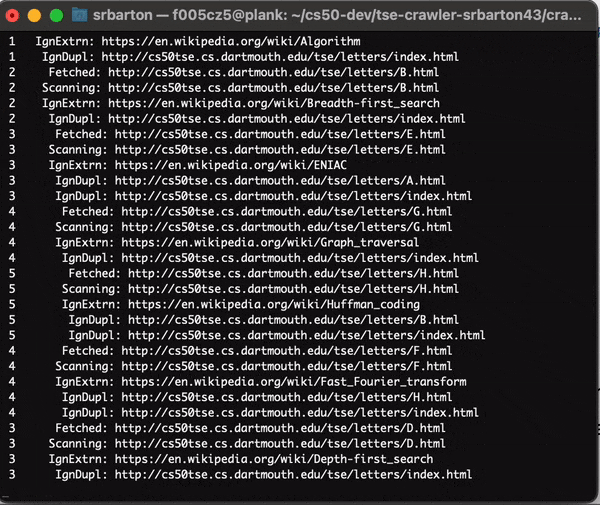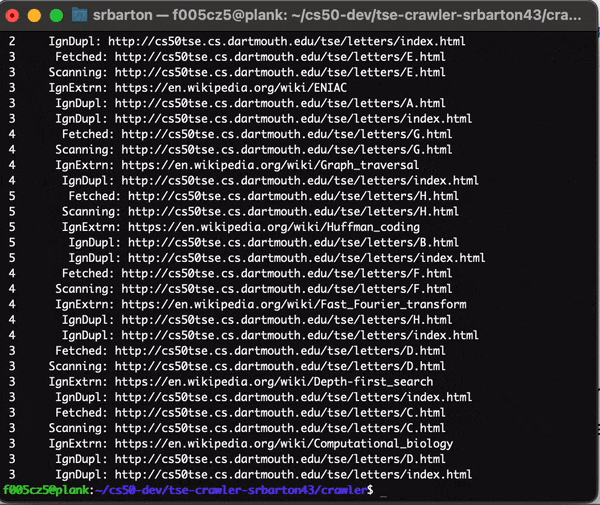
The Crawler in Action
Indexer Implementation
The indexer module produces an index file which stores the lookup table mapping each keyword to their host URLs with the number of ocurrences.
It browses the page directory created by the crawler and uses this directory to construct the index.
The module uses one main data structure: an index structure which maps from word to (docID, #occurences) pairs.
The documentID is a unique ID for each webpage cached in the pageDirectory.
Usage:
./indexer pageDirectory indexFilename
Querier Implementation
The querier module is another standalone program which returns a page ranking according to a user’s query in stdin.
To use the querier program, it simply requires the index file (created by the indexer program) and the page directory (created by the crawler program).
It reads the index file into memory as an index data structure.
The program parses each query and uses the union and intersection keywords (‘AND’ vs ‘OR’) in the query and uses the index to return a ranked list of URLs based on each score.
Usage:
./querier pageDirectory indexFilename
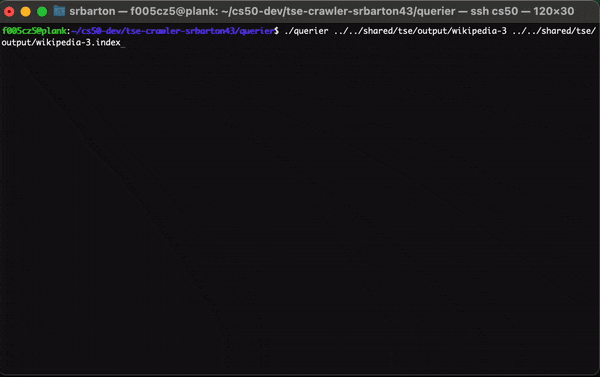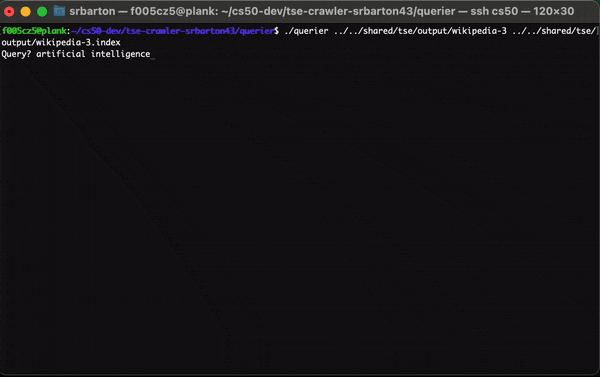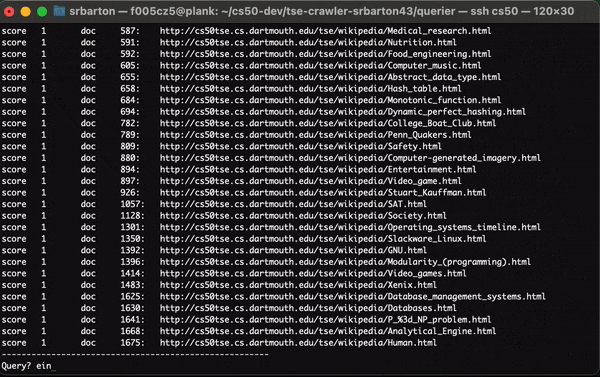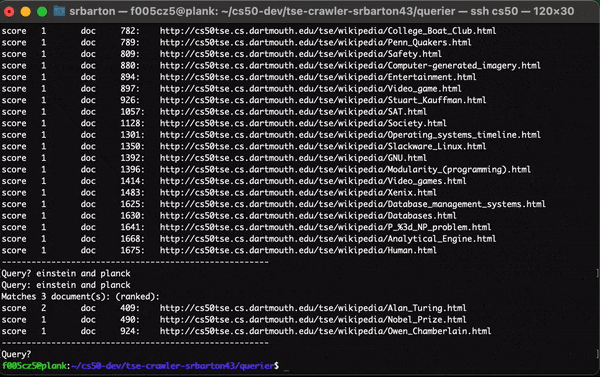
Querier in Action